Why We Treated Our AI Orchestrator Like Terraform
We built a coding agent. Then we realized we built it wrong. AI Agents aren't 'Chatbots', they are 'Infrastructure State Machines'.
Posted on January 30, 2025 by Cabin crew team
We built a coding agent. Then we realized we built it wrong. AI Agents aren't 'Chatbots', they are 'Infrastructure State Machines'.
Posted on January 30, 2025 by Cabin crew team
We built a coding agent. Then we realized we built it wrong. We realized that AI Agents aren’t “Chatbots”, they are “Infrastructure State Machines”.
When we started building Cabin Crew, we did what everyone else was doing: we built a chat interface for AI coding.
The workflow looked like this:
This felt natural. It’s how we interact with ChatGPT, Claude, and every other LLM interface.
But it was fundamentally broken for production use.
The conversation was ephemeral. If the AI generated buggy code, we had no record of:
The chat log was just text. It wasn’t structured, versioned, or cryptographically signed.
The human was the integration layer. The AI generated code, but the human had to:
This introduced errors. A typo during copy-paste could break the entire application.
If the AI-generated code broke production, how do you roll back? You can’t just “undo” a chat conversation. You have to manually revert the changes, but you don’t have a clean diff of what the AI changed.
The AI could generate anything. There was no way to enforce:
The human was supposed to catch these issues during review. But humans are slow, and AI is fast.
One day, we were debugging a failed deployment, and someone said:
“This feels like running
terraform applywithout runningterraform planfirst.”
That’s when it clicked.
AI Agents aren’t chatbots. They’re infrastructure state machines.
Think about how Terraform works:
.tf files)This is a two-phase commit:
We realized: This is exactly what AI coding needs.
We redesigned Cabin Crew to follow Terraform’s architecture:
The AI Agent runs in safe mode. It:
But it executes no side effects. It doesn’t:
The output is a structured artifact:
{
"plan_id": "plan-12345",
"issue": "Add user authentication",
"changes": [
{
"file": "src/auth.ts",
"action": "create",
"diff": "...",
"hash": "sha256:a1b2c3..."
},
{
"file": "src/routes.ts",
"action": "modify",
"diff": "...",
"hash": "sha256:d4e5f6..."
}
],
"dependencies": ["bcrypt", "jsonwebtoken"],
"tests": ["auth.test.ts"]
}
This is the Flight Plan—a declaration of intent.
The Orchestrator pauses execution. It feeds the plan into a Policy Engine (OPA):
package code_review
# Check for secrets
deny[msg] {
input.changes[_].diff contains "API_KEY"
msg := "Code contains potential secret"
}
# Check for destructive changes
deny[msg] {
input.changes[_].file == "database/schema.sql"
input.changes[_].action == "delete"
msg := "Cannot delete database schema without approval"
}
# Check for new dependencies
deny[msg] {
new_dep := input.dependencies[_]
not new_dep in data.approved_packages
msg := sprintf("Unapproved dependency: %s", [new_dep])
}
If any policy fails, the workflow halts. The plan is rejected.
Only if the plan passes all policies, the Agent re-runs in write mode. It receives:
The Agent then:
But it can only execute the exact plan that was approved. If it tries to make additional changes, the State Token validation fails.
This led to a key architectural decision: separate the Generator (Dev Engine) from the Executor (Git Engine).
Responsible for:
This is a pure function. Given the same input, it should produce the same output (as much as an LLM can).
Responsible for:
This is a side-effecting function. It modifies the external world.
By separating these, we gain:
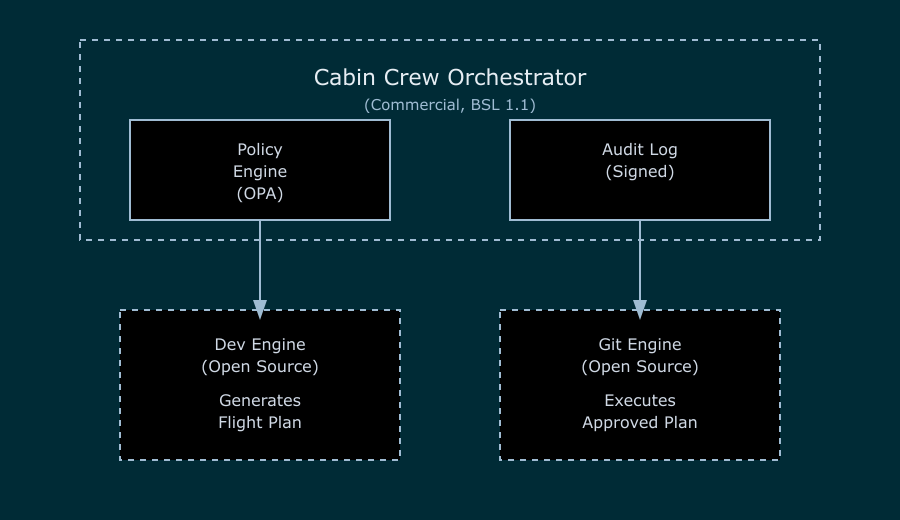
This led to the current Cabin Crew architecture:

The brain. It:
This is the trust layer. It’s commercial (BSL 1.1) because enterprises need guarantees that governance is enforced.
The workers. They:
These are commodities. We want the community to build better, faster engines. They’re Apache 2.0 licensed.
This architecture gives us:
The Dev Engine doesn’t need to know about git. The Git Engine doesn’t need to know about LLMs. The Orchestrator doesn’t need to know about either.
Each component has a single responsibility.
Don’t like our Dev Engine? Build your own. As long as it speaks the Cabin Crew Protocol (JSON over stdin/stdout), the Orchestrator can use it.
Want to use a different LLM? Swap out the model. The protocol doesn’t care.
Every step is logged:
And it’s all cryptographically signed.
Policies are enforced before execution. The AI can’t “accidentally” commit secrets or delete the database. The policy blocks it.
Building Cabin Crew taught us that AI coding isn’t about conversation. It’s about orchestration.
You don’t “chat” with Terraform. You declare state, review plans, and apply changes.
AI Agents should work the same way.
Stop building chatbots. Start building state machines.
Interested in the architecture? Check out The Orchestrator or read the Cabin Crew Protocol.